工作来源
DSN 2023
工作背景
CARO 在 1991 年提出了命名规范,但由于后续恶意软件的爆炸式增长与反病毒引擎的多种多样,恶意软件命名完全分散。
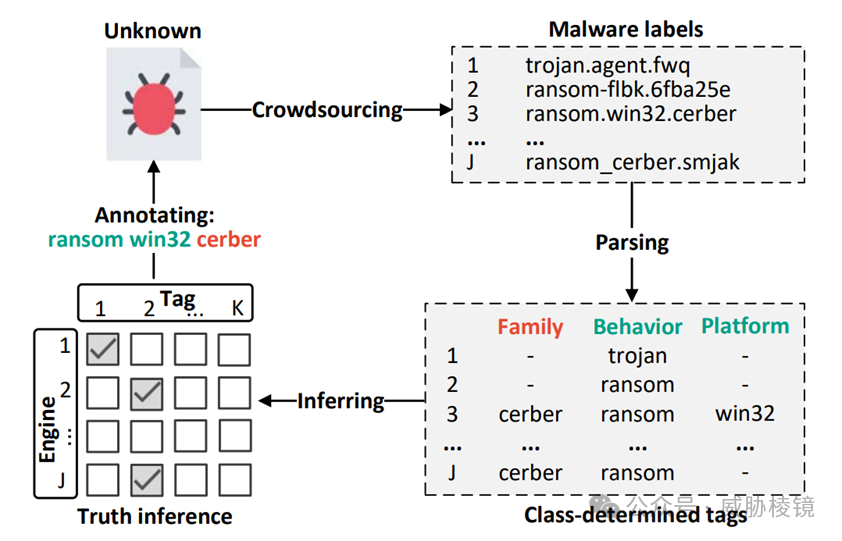
近年来机器学习的兴起,需要大量已标注的数据。利用如 VirusTotal 等多引擎扫描检测服务,即可利用多种引擎收集恶意软件标签。业界已经广泛采用这种方式来构建基准数据集,标签混乱会产生诸多影响。
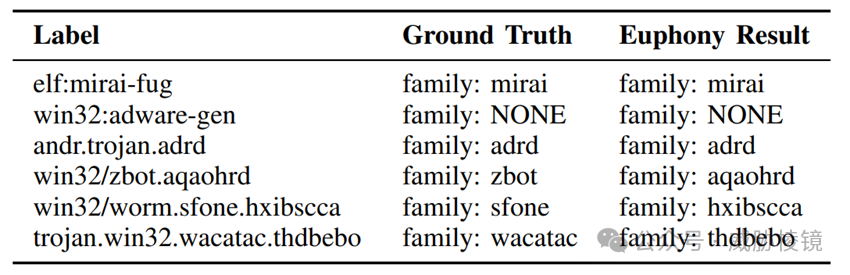
尽管恶意软件标签的命名模式是个黑盒,但从数据中可以发现在将行为标签与平台标签当作定位器时,家族标签总是会出现在相同的上下文中。
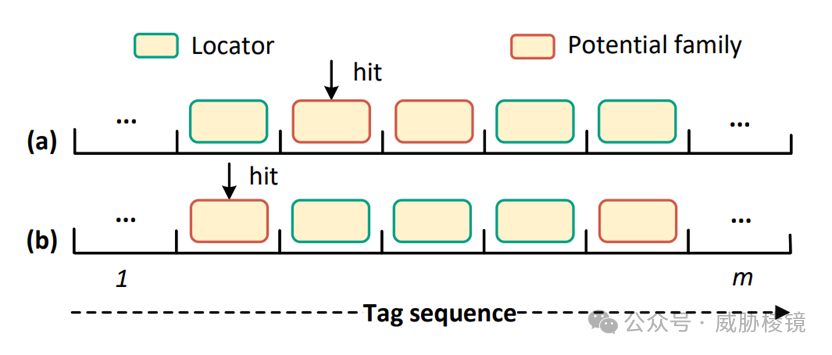
恶意软件的行为标签与平台标签的总量很小,通常是语义化的、可识别的。
工作设计
架构如下所示:
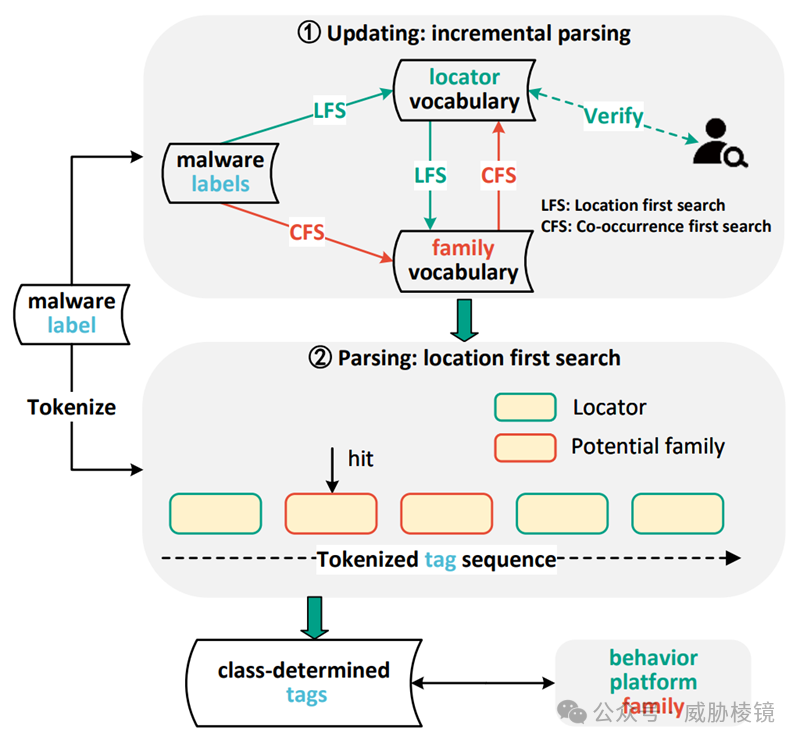
一共由两个模块组成:
更新模块:利用增量解析方案更新定位器词汇表。
解析模块:依赖最新的定位器词汇与位置优先搜索算法,输出类别确定的标签。
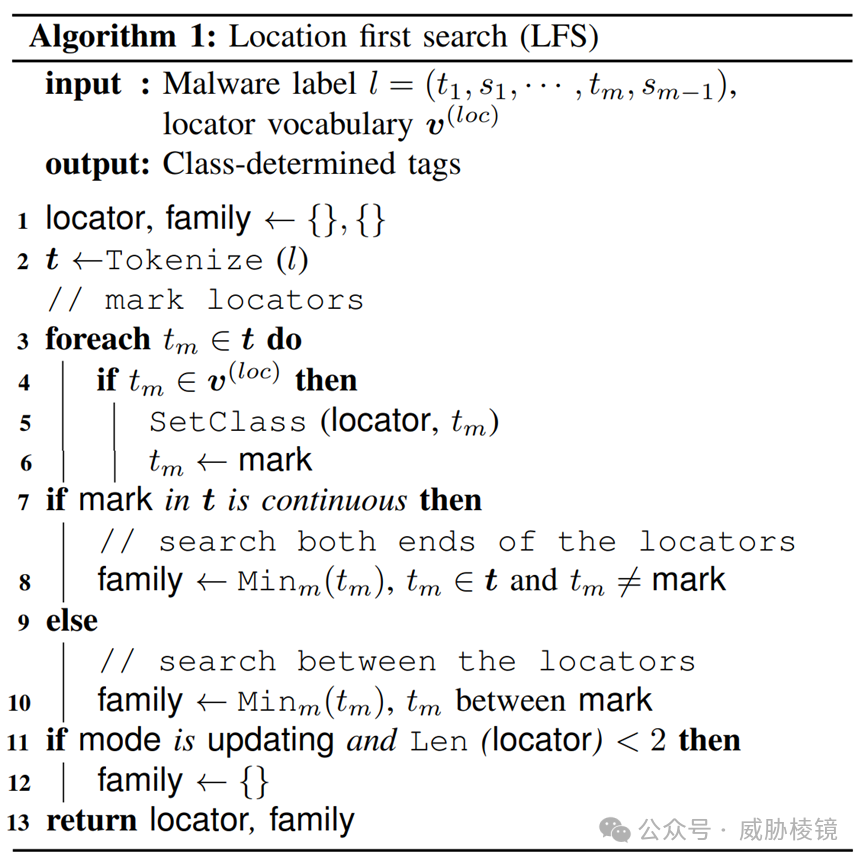
位置优先搜索算法有两种模式,解析模式下定位器词汇表完全更新。在更新模式下,定位器词汇表并不完整。为了保证标签更新的质量,位置优先搜索算法只保留大于两个定位器检索发现的家族标签。
更新模块
更新模块基于共现优先搜索(CFS)算法使用家族标签查找新出现的定位器,如下所示。

查看家族标签与其他标签同时出现的次数,超过阈值的被认为是潜在的定位器。AVClass 检测杂项标签的方式与此较为类似,只是 AVClass 会使用实际的家族标签,CFS 利用 LFS 自动检索家族标签。
工作准备
训练时使用 VirusShare 在 2012 年到 2022 年收集的 890 万文件,通过 VirusTotal 获取 59 个检测引擎给出的 2100 万个恶意软件标签。
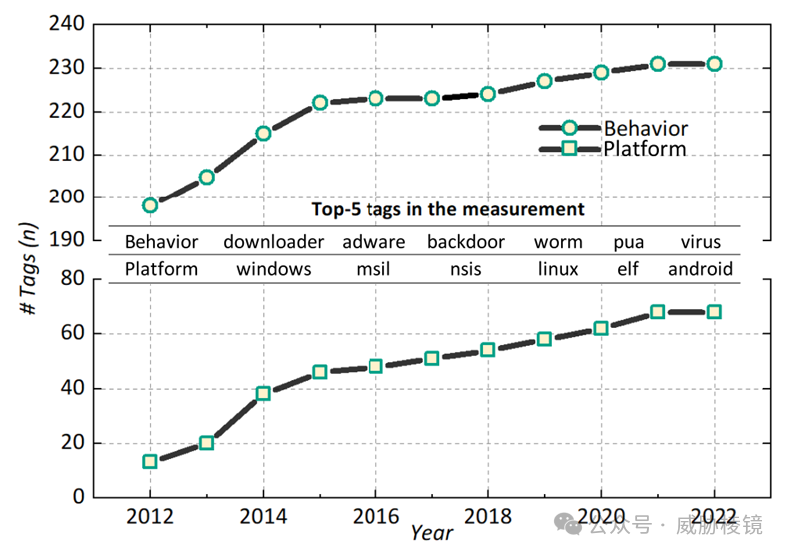
共计 68 个平台标签、231 个行为标签、6.1 万个家族标签,由上可见行为标签与平台标签的增长相对缓慢。
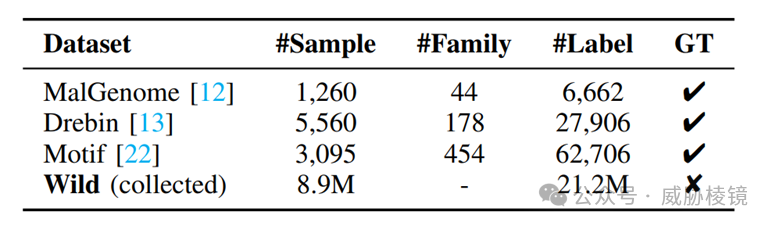
评估时额外使用的数据集如下所示:
工作评估
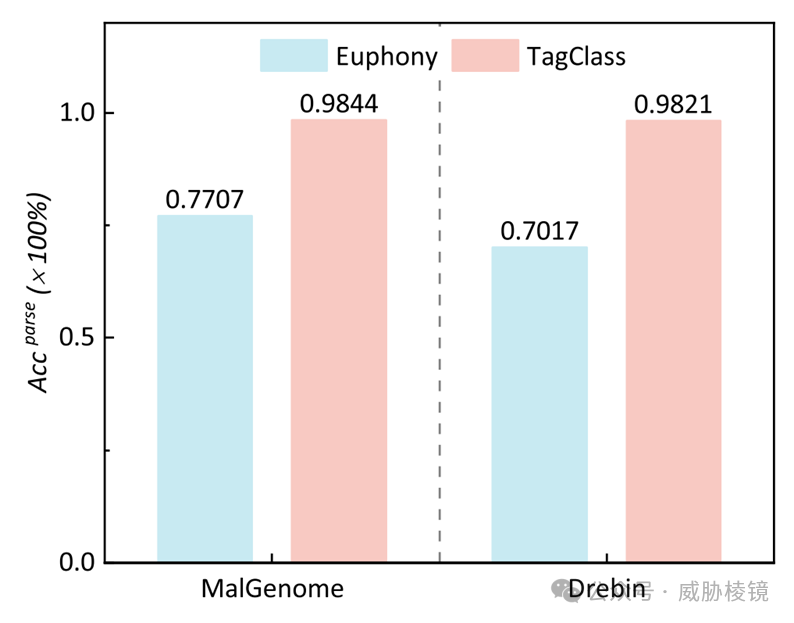
解析准确度
在 MalGenome 与 Drebin 上,TagClass 比 Euphony 分别好了 21% 与 28%。
定位器更新
初始定位器收集了 61 个,增量解析收敛速度很快,三轮内就能达到稳定。
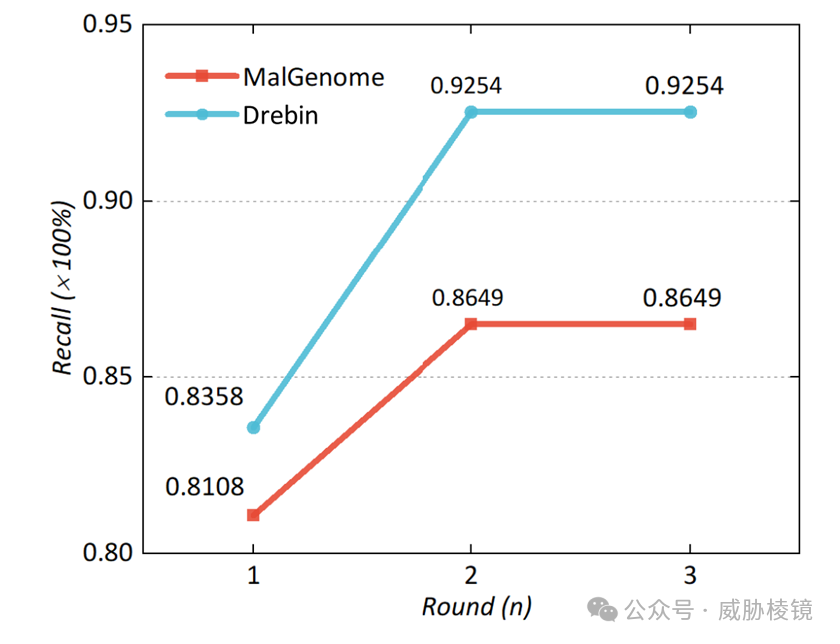
定位失败的那些,大多数是由于恶意软件标签中没有家族标签与其临近。另外一小部分是,LFS 不能在只有一个定位器的情况下发现新家族标签,CFS 也不能利用这些标签找到新的定位器。
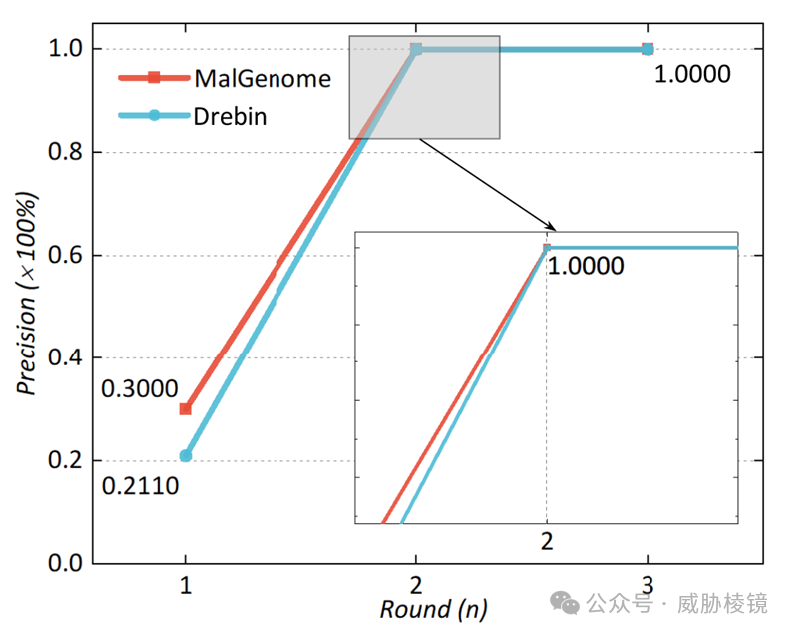
第一轮的 TagClass 在 MalGenome 与 Drebin 上实现了 30% 与 21.2%的准确度,并且输出了 20 个潜在定位器与 109 个潜在定位器,数据量越大人工的负担也越大。
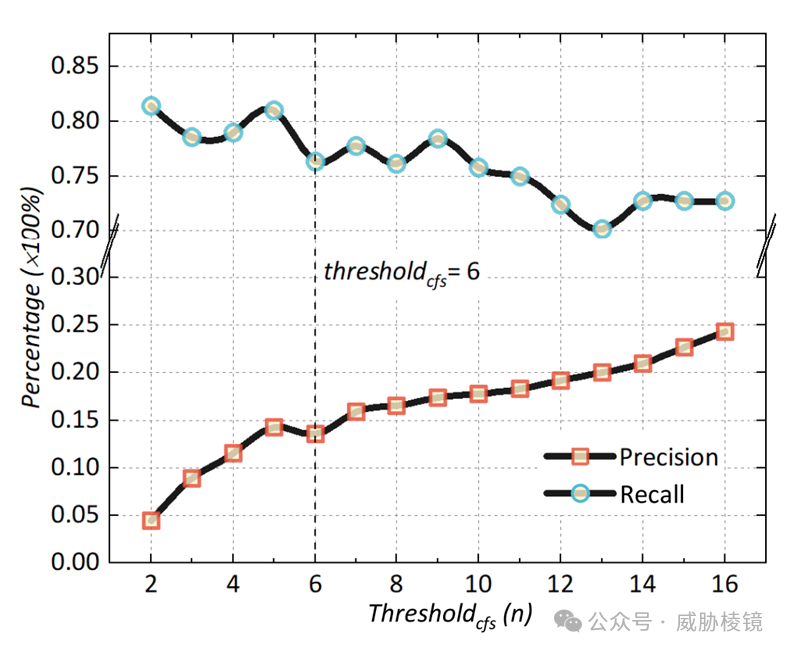
增大 thresholdcfs 时,准确度会上升,召回率会略有下降。
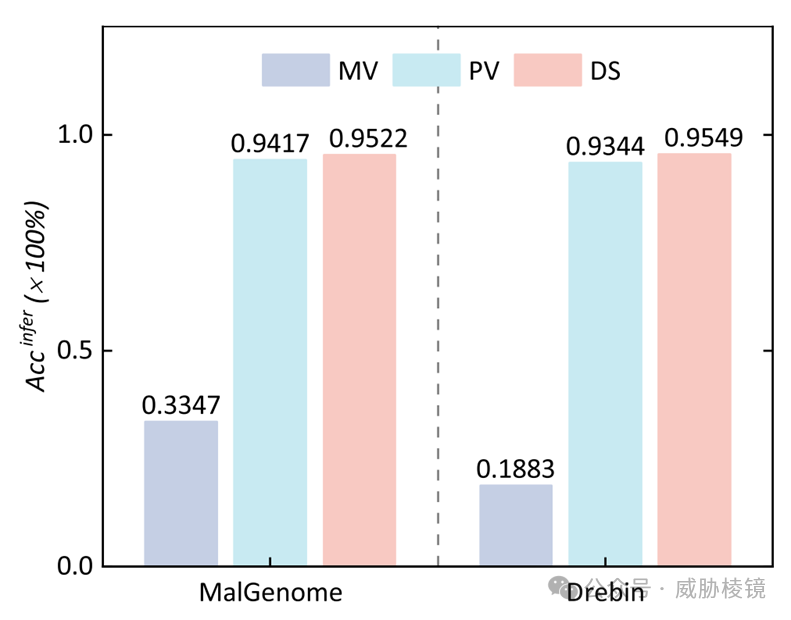
三种(多数投票/MV,复数投票/PV,DS)恶意软件标签推断方法比较如下,DS 的效果要比多数投票与复数投票都好。
工作思考
前面提到过恶意软件命名的系列坑,算是补了一个吧,其实这也是在手里压了一年的存稿了。这块做的人不算多,近几年的工作也算是越做越明朗了。这个工作应该也是非常值得学习的,后续应该会有更好的工作出现。